This blog post originally appeared on crypto.is. We've since shut down that website, so I have copied the blog post back to my own for archival purposes.
A remailer is slang for a system that allows you to send anonymous email to a recipient. It re-mails messages for you. There are a lot of reasons why people would want to send anonymous emails.
- Researchers and Survey Participants, who don't want to expose their opinions on sensitive topics like religion or politics
- Whistleblowers, who want to report illegal activity of a coworker, government or company - but can't risk losing their job or being prosecuted
- Journalists, who want to correspond with a source without exposing the source, or being tracked down themselves.
- Law Enforcement, who want to communicate with confidential sources or undercover agents without risking their operational security
- Activists, protesting against repressive regimes like the ones we've seen in the Middle East
- Consumers, who want to send feedback on a product or service
- Individuals who don't trust their Internet Service Provider or Network Admin
In a series of blog posts, we're going to look at the theory and implementation of different remailing systems. We'll assume you're familiar with some basics of cryptography - symmetric (secret-key) and asymmetric (public key) cryptography for the most part - and with the general idea of how Tor works. If you don't know these things, you'll probably be able to follow along well enough, but may miss some of the comparisons.
From The Ground Up
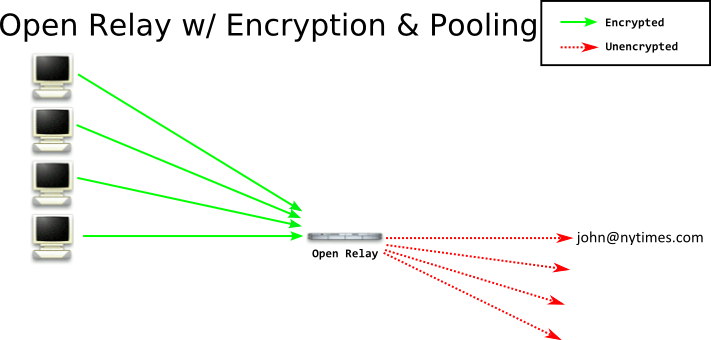
If our goal is to send anonymous email, what is the simplest way we can accomplish this? How about we just create an Open Relay that will not forward identifying information? It will recieve a connection, process the SMTP message, and send it on to the recipient, leaving out any of the sender's information.

While this system does deliver mail - there's a number of problems that can compromise your anonymity. For example, if you're being watched by an attacker, they can see the email you're sending! SMTP goes over plaintext by default. Clearly the solution is to encrypt the message so an attacker watching you cannot see it. This could be done with TLS inside the SMTP conversation or via an out-of-band system such as PGP.

This gains you some confidentiality, but there are still a number of issues. Now, let us assume the attacker was watching the relay. They would see the relay sending a message (and what the message was, and to whom) right after you connected to them. They are able to correlate that message to you in nearly all situations. To mitigate this correlation attack, the relay needs to hang onto a message for a little bit before it actually sends the message on. If it collects a number of messages in a pool, and then flushes the pool, an attacker has a harder time figuring out who was sending a message to who. If they watch the relay, they will know Alice, Bob, Charlie, and Dave sent messages M, N, O, and P - but not which person sent which message.There are attacks on the pooling we presented, but we'll leave those to another blog post.
This system still has several open questions. For example, how did you learn about this relay, and how did you learn its public key? This authentication step is incredibly difficult - and the general approach is to create some central directory service - that's the technique used by SSL on the Internet, DNSSEC, and even the Tor Project. There are advantages and disadvantages of this: obviously a directory service is a centralized point of failure or censorship. However if a central directory service is not present, attackers can perform more successfull correlation attacks by considering who knows about what relays. Having a central directory service ensures all clients know about all relays.
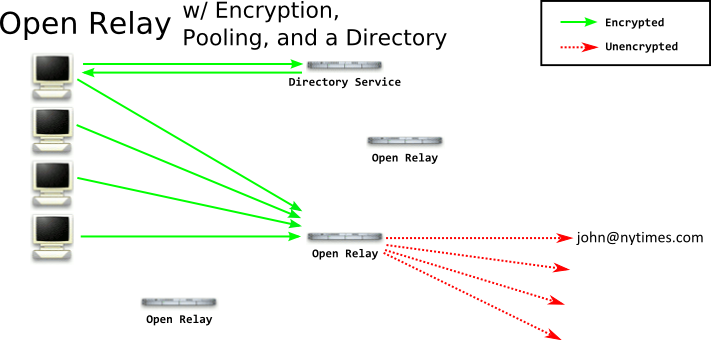
So at this point our client will connect to a directory, get the list of all relays, and choose one at random. (If they chose the same one all the time, correlation would be much easier.) The client will connect to the relay, send their message, and the relay will hang onto it for a bit, collecting more messages, before forwarding it on. But consider this - since you're picking a relay at random - it's possible the relay itself may be run by an adversary! If anyone can run a relay, so can your adversary. Eventually you'll probably forward a message through that relay, and they can inspect the message and see who is sending it. To overcome the relay itself being run by the adversary, we need to perform onion routing.
Onion routing is when you deliver an encrypted message to a node, who decrypts it and finds an encrypted package for another node. They can't decrypt this package, so all they can do is pass it to that next node - who decrypts it, and finds yet another encrypted package. All the way down the line until the last node finds the actual message, and delivers it. By the time the package reaches the last node - the last node doesn't know who the message came from! And the first node doesn't know who the package is being delivered to or what it says.
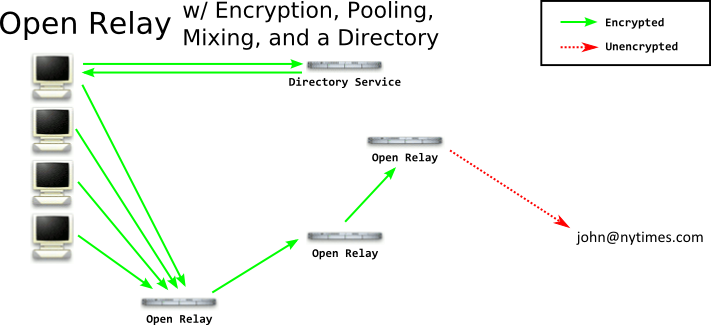
While there are some tweaks in the actual implementations - which we will get to in future blog posts - this is basically how remailers work. Let's look at it in-depth.
The System Completed
When you want to send an email, you first contact some form of directory service that tells you about the existing remailer nodes in the network. You get the nodes, their public keys, and some statistics about their past reliability. Because the directory service is telling you about the nodes and their keys - it's important that this service is trusted. It'd be possible for a malicious directory service to tell you only about malicious nodes. We'll talk more about Directory Servers and attacks on them later.

After you've gotten the list of remailer nodes from the directory service, you choose a path through them. The path can (theoretically) be any length that you like, and you choose the nodes at random - although you usually take into account their reliability. This doesn't have to be done by the user, and is usually done automatically by the client software. One of the many subtleties of maintaining anonymity is choosing a path in the same manner as everyone else choosing a path - if one implementation chooses 3 hops, and another 5 hops - this information can be used by an adversary.
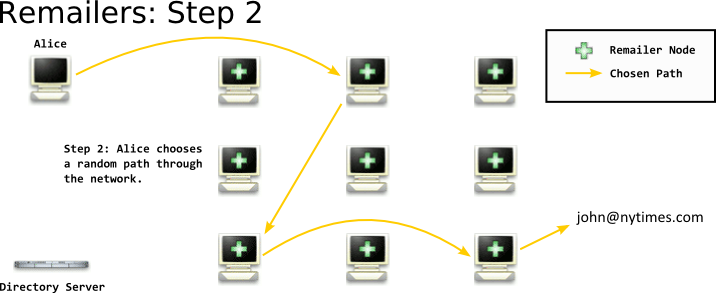
After you've chosen your path through the network, you take the email you want to send, and encrypt it in a package to each remailer - like Russian Dolls - and send it off through the network.
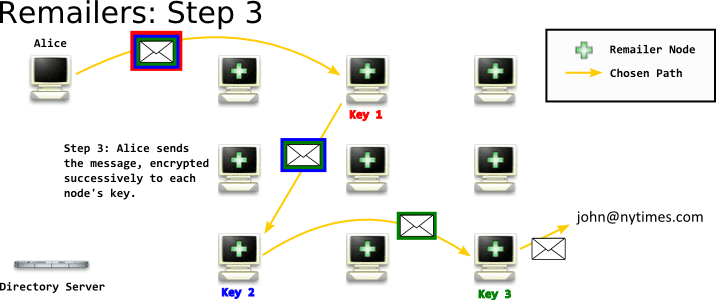
By encrypting it successively to each hop in your path, you ensure that each node knows the least possible about who you are, who you're e-mailing, and the contents of the message. By the time the message reaches the last hop, the last hop's administrator doesn't know who sent the message. They even don't know who would know who sent the message.
| Who | Who they see talking | What they see | What they don't know |
|---|---|---|---|
| Network Observer between You & First Hop |
You -> First Hop | 
| Second & Third hops, Recipient, Message |
| First Hop | You -> Second Hop | 
| Third hop, Recipient, Message |
| Network Observer between First & Second Hops |
First Hop -> Second Hop | 
| Sender (You), Third hop, Recipient, Message |
| Second Hop | First Hop -> Third Hop | 
| Sender (You), Recipient, Message |
| Network Observer between Second & Third Hops |
Second Hop -> Third Hop | 
| Sender (You), First Hop, Recipient, Message |
| Third Hop | Second Hop -> Recipient | 
| Sender (You), First Hop |
| Network Observer between Third Hop & Recipient |
Third Hop -> Recipient | 
| Sender (You), First & Second Hops |
| Recipient | Third Hop -> Them |
| Sender (You), First & Second Hops |
In Comparison to Tor
If you're familiar with Tor, you may be thinking that this is just like it. And while it does look very similar to Tor, there are a few major differences in the details.
High Latency and Pooling
Latency is a measure of time delay experienced in a system. If you run ping 127.0.0.1 you'll get a response back immediately - there was no latency. But if you run ping 8.8.8.8 you will see some (probably small) number of milliseconds elapse when getting a response. That's latency. A 'Low Latency' network means as soon as a node receives a packet, it sends it out. A 'High Latency' network means a node will hold onto a message for some amount of time before sending it out.
Traffic Analysis is a huge part of network design. If an attacker is watching the network (and we generally assume they are) - how much information do they gain by watching packet paths, sizes, and times, and how easy is it? If you see a network flow from Alice to Bob, and Bob to Charlie - those flows will probably be matchable. With regard to defending against Traffic Analysis, High Latency is preferable - being able to hold onto a packet for any length of time before sending it on gives you a lot more options.
Tor is a 'Low Latency' network - it has no choice because it's infeasible to browse the Internet with minute-long (or longer) delays during page loads. However, email can have delays - if an email doesn't arrive for 30 minutes or an hour, it's generally not a problem. So Remailers can afford to be a High Latency network. They will accumulate a number of messages in a pool, and then when the pool is a certain size, will send the messages out. There are multiple algorithms for pooling, and we'll go into more detail about them and pool attacks later.
Padding
If a network did not pad messages, and you send a packet of length 1337, each node will receive and send a packet of 1337 all the way to the final destination. This helps traffic analysis attacks, because someone watching a node can see the sizes of the packets received and sent, and it makes it easier to track the traffic across nodes - even when multiple people are using the nodes.
Tor pads messages into 512-byte cells. If you want to send 1337 bytes of data, it will (probably) be sent in 3 separate cells. Remailers pad all messages also, but to a larger size (on the order of 10 or 28 KB). We'll go into more detail about padding, and what happens when a message is larger than the chosen pad size - but the point is padding makes it more difficult to correlate messages, and when combined with pooling helps defend against traffic analysis.
Conclusion
We hope this is an understandable introduction to remailers. In our next post we'll look at two existing remailer networks and some of the subtleties of their designs. We hope to produce a series of remailer blog posts, eventually going into detail about topics such as pooling algorithms and attacks, directory services attacks, mix packet formats, traffic analysis, padding sizes, and other topics that must be considered when designing remailer networks.
This blog post is licensed under Creative Commons Attribution 3.0 United States License and is inspired by, and makes heavy use of, the images produced by the EFF & Tor Project here.
required, hidden, gravatared
required, markdown enabled (help)
* item 2
* item 3
are treated like code:
if 1 * 2 < 3:
print "hello, world!"
are treated like code: